
Wow! You have come so far in this blog, i am sure you are gonna enjoy this one after KMeans and KNN.
"The inflation next year will be the most terrifying thing man-kind has ever seen."
Pretty easy to classify this as a negative statement, right?
How about telling how similiar following statement is to the one above:
"Looking at the inflation from a one year perspective will terrify man-kind in every aspect."
So although both sentences have different structures with specific words being changed, you'd say these are pretty much exact the same. But how can we tell a machine to tell us not only how similiar texts are and what kind of sentiment they give the reader?
First let us take a look at Similiarity:
In our first approach to define rules that would make it easy to compare similiarity of text's and therefore sentences. We'll take following sentences as an example:
- "John loves apples and video games."
- "Sam is loving apples and thinks blockchain is the future."
From a scale from 0 to 1, where 0 is "not in anyway" and 1 is "very", how similiar are these sentences for you? Write your answer down and see if you are right.
If we create a list of all words appearing in both sentences we will get something like the following
![]()
Notice how stop/ unnecessary words are filtered away and the other ones have been lemmatized (since love is the same as loving).
Now if a specific word is being mentioned in sentence A and B in the list, it will receive a 1, otherwise 0. In the example of John this looks like this:
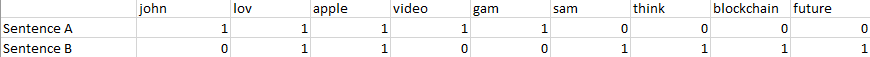
As a end result, there will be lists of 1's and 0's in different quantity and order called vectors. How do we measure the similarity of these vectors?
As always, math is our friend. The so called cosine of the angle between these vectors will give us an answer between 0 and 1, where 1 is identical and 0 is nothing alike. We can simply calculate it by
![]() In our case, A =x and B = y. Remember our little guessing game? Bring back your guess and lets compare them. Sentence A and B are 36% similiar. Not too bad, how did you guess? Let me know it in the comments. The process of creating vectors out of sentences is called "Vectorization" and one of the main tools in the nlp area.
In our case, A =x and B = y. Remember our little guessing game? Bring back your guess and lets compare them. Sentence A and B are 36% similiar. Not too bad, how did you guess? Let me know it in the comments. The process of creating vectors out of sentences is called "Vectorization" and one of the main tools in the nlp area.
Now lets see what sentiment analysis is:
Oops, the article already got a little bit too long. Make sure to follow me in order to receive news about the next article (SPOILER: Its gonna be about sentiment analysis).
TL;DR: One of the main areas of Natrual Language Processing belongs to checking how similiar texts are. This is being done by vectorizing these and calculating the cosine similiarity.








