
If you haven't had the chance to read my Brief introduction to machine learning, i encourage you to quickly switch tabs and take a look. Let's continue the series now.
Congratulations! Your city has announced their new candidate for president election-day and surprise surprise it is you. In order to succeed in your campaign there is the desire of finding people who haven't voted yet. Instead of choosing people by random, you concretly want to target voters, who haven't given their vote to your party in the past so you can concentrate on gaining more trust and winning the election. But......how do you choose if a new voter is likely to be for or against your party?
These are problems people (alright in this these are rather special people) encounter everyday (or every 4 years, you will decide) which can be solved by K-Nearest-Neighbours (KNN). This method is under the belt of supervised learning techniques and probably the easiest of all of the upcoming methods. The essential key feature of KNN is the aim of classifying a data point, wether it is a person or anything else, by other data points which share the most amount of features that are the same or nearest approximately. I will just stop here and show you an example.
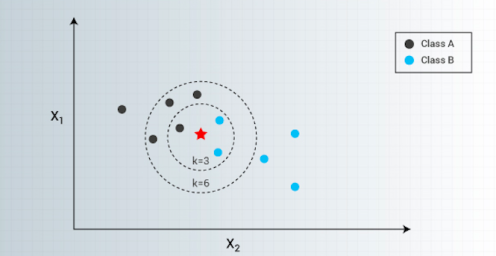
Some one puts the red star in the middle of the plot and forces you to decide if it should be labeled as a black (Class A) or blue (Class B) [I dont care if the color is rather turquoise than blue, i am partially colorblind so move on]. How would you decide which side to pick ( of course without the circles being drawn already)? A KNN algorithm would take an arbitrarily choosen k (hence K in KNN) and decide which of the nearest neighbours have the shortest amount of distance. If k were 3, our red star should be classified as a blue circle and so be labeled as Class B. Moving up to k=6 means we will know consider our evaluation and label the star as Class A/ black dot.
Did you recognize the pattern? For every new data point given from a set we can just pick a wanted k and choose how our point can be classified. This might be pretty vague but what do you want? No one said it was complex. Let us come back to our initial case revolving around the elections. Your assistant gives a list of all the people who are being eligible to vote and haven't voted. Since there are no records of past votings (I hope so), you will decide on the one side which k to choose, and on the other side which features you want to consider. This can be anything from the votes of neighbours to the height or weight of surrounding people (Not that overweight is highly correlated with one or another party but just take it as it is). If the first voter on your list has 3 neighbours, 1 left - 1 right- 1 in front on the other side of the street, and you choose k=3, we will take a look at their votes and decide if our voter is interesting for us or not. Look at that! His left neighbour voted your party but the people in front and right have voted for the enemy party, now we can label our dummy as a potential new gainable vote. Let's finish our work and visit him after work (Not in any aggressive or violence way, just knock on his door and ask if he needs any information or help regarding the election)
This was obviously a very very simple example but labeling a new point in space by features given in near points with the smallest distance still stands true for a variety of problems. If there are any questions regarding the math behind it or source recommendations leave a comment and make sure to follow. The next technique will be even funnier (if KNN wasn't funny it is pretty good since there is no standard set yet).
TL;DR: New data points are being labeled by deciding if other points share same attributes and features. Important points are being choosen by their distance to the new point. The amount of deciding points can be choosen by having K set to your wishes. After this step you will take a look at the Nearest Neighbours in order to decide how the new point can be classified. -> hence K-Nearest-Neighbours








