
Distributed hash tables (DHTs) are actually a much more mature, flexible and important decentralization technology than is blockchain. Blockchains are actually even still centralized around a canonical ledger or the single massive replicated record of events (i.e., a single view of history) and as such are rather limited in application (to whatever needs to be universally agreed upon on a global network-wide scale of consensus, which is also kind of arguably realistically impossible). So, DHTs deserve more attention than they've been given in the context of re-decentralizing the Internet as knowledge of DHT algorithms is going to be a key ingredient in future developments of distributed and decentralized applications.
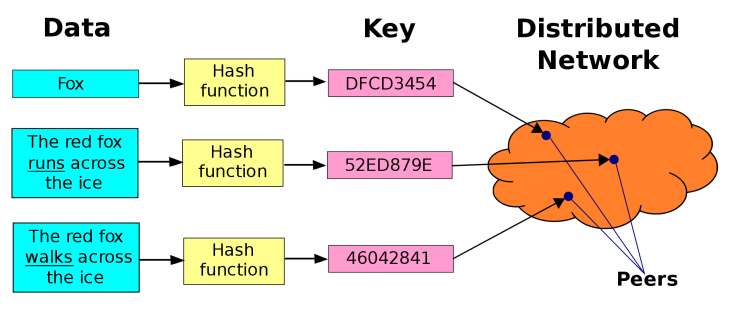
A distributed hash table is basically a decentralized storage system of key-value pairs where the values mapped against keys can be any arbitrary form of data. Each node in a DHT is responsible for keys along with the corresponding values they map to and any node can efficiently retrieve the value associated with a given key in its network. In other words, a DHT is basically a map of values and their references of where they can be located within the network topology of peers. Which basically makes it an already-sharded distributed data model. Why DHTs haven't been more widely discussed, considered and used instead of blockchains for most relevant applications is a bit strange, given their general applicability as decentralized technology. There's numerous ways in which a DHT can be designed and implemented based on the arrangements of how keys correspond to values, some of which we'll explore in more detail further along.
DHTs have the following properties:
- Decentralised & Autonomous: Nodes collectively form the system without any central authority.
- Fault Tolerant: System is reliable with lots of nodes joining, leaving, and failing at all times.
- Scalable: System should function efficiently with even thousands or millions of nodes.
DHTs commonly have a two-method interface for applications:
- put or insert (key, value) — input a key-value (k, v) data item into the DHT.
- get or lookup (key) — return the value (v) associated with key (k).
The nodes in a DHT are connected together through a virtual overlay network of connected neighboring nodes such that the network allows for the nodes to find any given key in the key-space (name space). A DHT provides a unified platform for managing application data as a flat identifier-based routing and location framework with a simple API to applications that generalizes for a wide range of possible services and applications (and is not an application-specific protocol). A DHT usually has the following desirable properties:
- Efficiency in routing: A DHT overlay is structured so that queries for keys may be resolved quickly. Typical DHT schemes have a O(log n) bound on the length of search path (in overlay hops). To reduce routing delay, in recent years, locality-aware DHTs have been proposed so that routing hops are of short Internet length by taking advantage of locality information.
- Scalability: Node storage and maintenance overhead grows only logarithmically (log) with the number of nodes in DHT. This leads to its high scalability to large number of users (no consensus bottlenecks the way there are in blockchains).
- Self-organization: A DHT protocol is fully distributed — node joins, departures and failures are automatically handled without the need of any kind of central coordination.
- Incremental deployability: A DHT overlay works for arbitrary number of nodes and adapts itself as the number of nodes changes. It is functional even with one node. This is a highly desirable feature as it enables deployment without interrupting normal operations when new nodes join the overlay.
- Robustness against node dynamics: Queries are resolved with high probability even under node dynamics. Further optimizations may further increase system robustness.
In designing a DHT to achieve the above desirable properties, several issues need to be considered:
- Node dynamics: Peers may join and leave at any rate and since no central server keeps record of the status of peers, the DHT structure must maintain itself to ensure correct and efficient routing dynamically.
- Overlay path stretch: Compared with IP routing, overlay routing to a certain node has in general higher latency, since overlapping traversals of some physical links is inevitable. The path stretch is defined as the ratio of the overlay route’s latency to the underlying IP route’s latency. In order to avoid large path stretch, DHT routes need to be optimized for low response time and such optimization techniques should be scalable to large groups.
- Hotspots: Application data is generally skewed in terms of access probability. For instance, in video streaming, some segment of a video may be more popular than the other. A DHT scheme needs to consider the high lookups for a particular key (i.e., popular segment) by load balancing request processing among many nodes. The load balancing algorithm should be scalable.
So-called k-buckets are lists of routing addresses of other nodes in the network (containing the IP address, port, and NodeID) that each node maintains — longer/longest-lived nodes are preferred (thereby one cannot overtake a node’s routing state by flooding the system with new nodes, thus also preventing certain types of DDoS attacks).
Examples of DHT-based application frameworks are Holochain and Scuttlebutt. Both implement DHTs as the public space of an app/service, with each individual agent/user/participant also storing their own append-only hashchain feed/record (basically a sort of local blockchain living on your device). This model is meant to make possible the running of large-scale applications like Facebook and Twitter in a distributed peer-to-peer fashion without massive centralized servers to manage complexity and enter as man-in-the-middle in the back-end of mediation and control.
Below is a quick overview of some of the well-known DHT designs and Holochain's specific modification of Kademlia.
Chord: Each Node Stores the Values for the Keys it is Responsible For
Chord is one of the four original DHT protocols/algorhitms (along with CAN, Tapestry, and Pastry) that was developed in MIT and introduced in 2001. Chord works by assigning keys to participating nodes and each node will store the values for the keys for which it is responsible (a node will discover the value for a given key by first locating the node responsible for that key).
Pastry: An Advanced Chord With Different Routing Metrics and Heuristics
Pastry is similar to Chord (based on Plaxton mesh like Tapestry with some differences) — key-value pairs are stored in a redundant peer-to-peer network of connected hosts and the protocol is bootstrapped by supplying it with the IP address of a peer already in the network and therefrom via the routing table which is dynamically built, updated and repaired. The protocol is also capable of using a routing metric supplied by an outside program, such as ping or traceroute, to establish the best routes to store in its routing table.
Kademlia: The Basis for Most Modern DHT Implementations
Kademlia was designed by Petar Maymounkov and David Mazières in 2002 and is implemented in a number of modern decentralized protocols including BitTorrent, IPFS, Swarm, Ethereum and Storj. In Kademlia's design a node's ID serves not solely for identification/identity, but the algorithm uses it to locate values (hashes or keywords) — in fact, the node ID provides a direct map to file hashes and that node stores information on where/how to obtain them. Kademilia is particularly resistant against attacks like denial-of-service since even if a whole set of nodes is flooded, this will have limited effect on network availability as the network will re-constitute itself by knitting the itself around these "holes".

Kademlia is a common DHT design that is distinct from previous models preceding it due to its simplicity. It uses a very simple XOR operation between two keys as its “distance” metric to decide which peers are closer to the data being searched for — i.e., the distance between two nodes is defined as the XOR of the nodes' IDs (as the binary representation of an unsigned integer). This makes for coding DHT applications much simpler as the distance metric is symmetric (distance(A, B) == distance(B, A)). This is how this looks like in Python ("^" in Python = XOR):
def distance(a, b):
return a^bThe chaotic, ad hoc topologies of the first generation peer-to-peer architectures have been superseded by such set of topologies (like Kademlia) with emergent order, provable properties and improved performance. Existing research DHTs, such as Chord, Kademlia and Pastry, therefore are starting points for the development of one's own custom schemes. Each has properties that can be combined in a multitude of ways and it's important to understand that these different properties are not tied to any particular DHT implementation.
XOR, or exclusive disjunction is a logical operation that essentially means "either one, but not both nor none", i.e. it outputs true only when inputs differ. In other words, it evaluates a statement as true if and only if one is true and the other is false.
The Kademlia protocol has four Remote Procedure Calls (RPCs) through which nodes communicate using UDP:
- PING: probes a node to check if it’s responsive/online,
- STORE: stores a key-value pair in a node,
- FIND_NODE: returns information about the k nodes closest to target id,
- FIND_VALUE: similar to the the above, only if the recipient has received a STORE for the given key, it just returns that corresponding stored value.
Here's a Kademlia implementation in Python that uses the asyncio library and documentation at kademlia.readthedocs.org.
Kademlia Implementation and Use in Ethereum
Node discovery in Ethereum's network stack is based on a slightly modified implementation of Kademlia. Ethereum makes use of the Kademlia XOR metric and the k-bucket struct, with lookup mostly used to discover new peers.
Kademlia in the Inter Planetary File System (IPFS)
The Inter-Planetary File System (IPFS) also implements Kademlia — with Coral DSHT and S/Kademlia extensions. In IPFS’s implementation, a NodeID contains a direct map to IPFS file hashes and each node also stores information on where to locate and get a file or a resource.
Kademlia in Swarm: Distributed Storage and Content Distribution for Ethereum and the Web 3.0
The primary purpose of Swarm is to provide a sufficiently decentralized and redundant store of Ethereum’s public record for dApp code and data (as well as blockchain data). Participants in the Swarm network are identified in the Kademlia DHT by the hash of their Ethereum address of the Swarm base account. This serves as their overlay address with proximity order calculated based on these addresses.
Holochain's rrDHT: Modified Kademlia Designed to Fit Holochain's Model
rrDHT is a modified Kademlia adapted/designed to Holochain’s agent-centric assumptions such that it embeds them deep into the design. Just like with Kademlia, agents and data live in the same address space which resembles a wheel. Agents share their public keys, source chain headers and public entries with other peers in a DHT, who collectively witness, validate, and hold copies of them, providing redundancy and data availability and giving the network the capacity to detect corruption. An agent’s address is based on their public key and an entry’s address is based on its hash which constitutes a content-addressable DHT where the keys are derived from their values.
Each agent has:
- a ‘storage arc’, which is the portion of the DHT in the range of which the agent claims to know about all involved data and enough other peers whose storage arcs overlap,
- a ‘query arc’, which is the portion of the DHT in which the agent claims to know about enough other peers whose storage arcs overlap,
- a few faraway peers to speed lookup times.
The storage and query arcs can be thought of respectively as small and large neighborhoods. In the small neighborhood everyone knows each other well, gossip/interact closely and take care of each other. And each agent has a different opinion of who their close neighbors are — one might extend that status to a node seven blocks away, but they might not extend the same status as one node may have more storage space and bandwidth but the other one seven blocks away may just be a smartphone or a Raspberry Pi and doesn't have as much resources to share or give away. The large neighborhood consists of the area where one knows their way around (the map of the network topology of what what's/who's where), but doesn't look out/interact for each other the same way as in the small neighborhood.
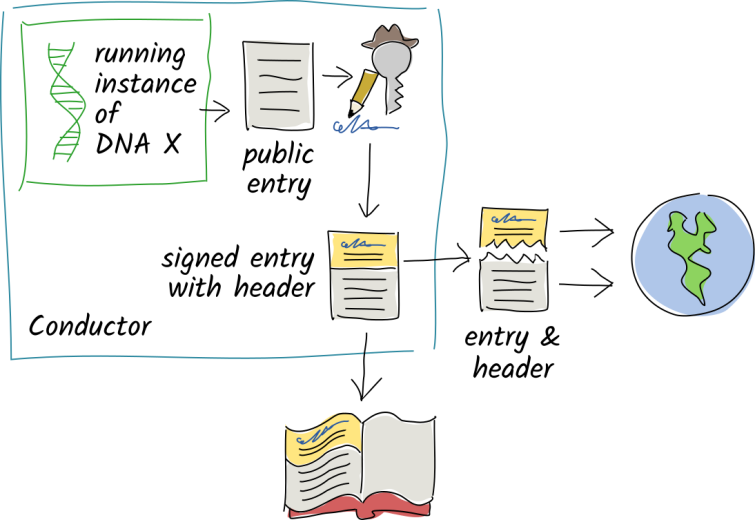
When you commit a private entry, it stays in your local source hashchain but its header is still shared.
Validators for a given entry are chosen on the basis of their address’ closeness to the entry’s address (as in the distance function between the two), so knowing the hash makes it easy to find the node holding a particular entry. This model is actually very similar and reflecting of how things do work in actuality of real life and the manner in which things register, notice, record and store information and memory about their surroundings. Where the monolithic blockchain model is designed to ensure an absolute single source of truth and network-wide consensus about validity of data — something that by its very definition and nature does not scale (and in the case of Bitcoin, perhaps — most likely — has never even meant to scale, but rather intended as a rogue back alley for channeling and re-routing specific capital flows without their being registered and accounted for in the established legal ways).
Conclusion
Distributed hash tables are actually a much more flexible decentralization technology that generalizes across the board and as such should be more widely studied, understood and taken up as a model within which to think and design distributed peer-to-peer applications. Consensus in DHT networks takes place as peer validation of pieces of scattered data as peers actively gossip about what goes on and the network health and as they use the same data or resource and validate it against the specific validation rules of the application they run. Peers may also mutually audit each other's records as they countersign interactions/transactions between each other. In other words, it works more as collectively organized immunity in detecting corruption or tampering and re-acting to it (possibly black listing IPs and peers).
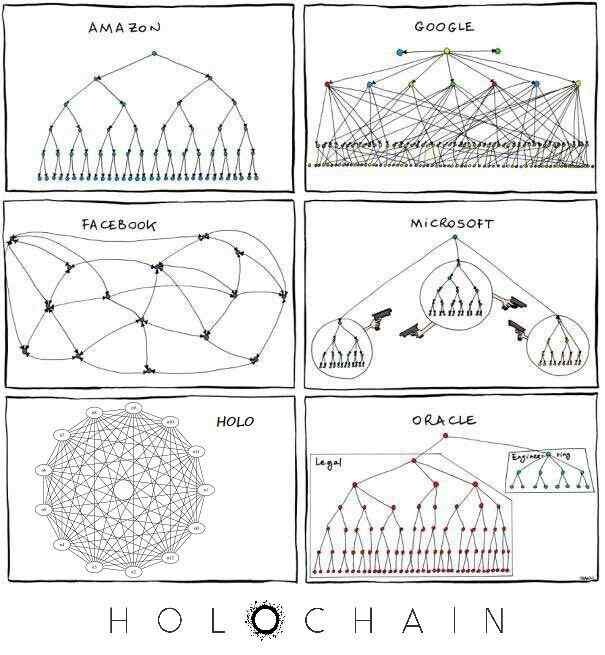
Comparison between the network topologies and networked architectures between Amazon, Google, Facebook, Microsoft and Oracle's server-client centralized models and Holochain's DHT-based agent-centric model of distribution.
As things develop and DHT-based apps and networks pick up momentum, it would also be important that they be capable of interacting with existing blockchains like Bitcoin and Ethereum in some capacity, but that may be taken care of in dedicated modules which serve as interface bridges that translate between the two systems and their conventions and data models. Upon having a closer look at Ethereum's layer 1 sharding solution to scalability, one can't help but notice just how closely it resembles a distributed hash table of sorts and wonder why was all this necessary only to re-discover the wheel and come up with the same practical solutions that had been there from the start. (Though of course, when talking Ethereum or other older chains, we're talking about a lot of actual value involved and secured in those networks, as well as a grown community and culture throughout the years, so obviously it's not as straightfoward and simple as that, but nonetheless something worth consideration and begging the questions.)








