
Introduction:
Due to its composability, security, and incredibly high liquidity, Ethereum has quickly become the most powerful platform for decentralized financial products. Ethereum’s lack of scalability however, has massively impacted its ability to grow alongside this current demand.
Thankfully, many different solutions have been in development over the last few years which are helping to scale the base layer (Ethereum) in a cost efficient and secure manner. These solutions can be broken down into, ‘how we are storing this data’ (on-chain or off-chain) and ‘how that data is computed’.
This series only considers technologies that support smart contracts; either currently, or will be, at a point in the future.
Data retention/storage:
With blockchain networks and economies, the term “on or off chain” comes up quite frequently when you are dealing with scaling solutions (particularly Ethereum). Below, we describe what these terms mean.
On-Chain Data
The terminology, “on-chain” simply means that the data from the scaling solutions are all stored directly on Ethereum. This means they are able to directly rely on the security of Ethereum to help prevent attacks on the network, and more importantly, guarantee assets, or funds stored on these smart contracts, remains safe.
Off-Chain Data
“Off-chain”, means that transactional data is stored off of Ethereum, essentially in separate “networks”. The result being that as these networks grow they have minimal impact on the scalability of Ethereum since Ethereum nodes don’t need to store any of that data on their own networks. In most cases, off-chain networks are able to process throughput much more effectively than ones who store data on-chain.
Computation:
With scaling solutions built on Ethereum, there are two core ways to communicate that data. zkProofs (zero-knowledge proofs) & Fraud Proofs.
zkProofs (e.g. SNARKs & STARKs)
zkProofs is a privacy focussed solution that uses cryptographic techniques to allow a party (or user) to prove a certain amount of information to a verifier (another party) without revealing any details about the data itself.
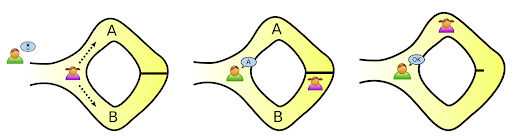
In this example of Ali Baba’s Cave, we have Alice and Frank and a circular cave. Halfway around the cave is a door, which can only be opened with a password. Frank wants to know if Alice knows this password, but Alice doesn’t want to reveal the password..
So Frank remains outside, and out of the line of sight, while Alice moves into the cave, choosing to go either along route A or route B.
Once Alice has entered the cave, then Frank is asked which direction she went (A or B).
Frank then enters the cave and shouts the name of the path he wants her to return on (A or B).
If Alice has the password then she has a 100% chance of returning down the correct path. If she doesn’t have the password, she has a 50% chance of guessing. By undertaking this test multiple times, the probability that Alice guesses the correct password is continually reduced and the probability that Alice does in fact know the password, becomes extremely likely1. This allows for Alice to “prove” she holds a certain amount of information (the proof), without revealing the secret to Frank (meaning he has zero-knowledge of it).
One of the first large scale use cases of zero-knowledge proofs as a form of computation was through the Z-Cash blockchain network, released in October 2016 by Zooko O’Hearn.
Z-Cash uses an advanced version of zkProofs called zkSNARKs. A zkSNARK stands for “Zero-Knowledge Succinct Non-Interactive Argument of Knowledge”. Similar to zkProofs, the use of “zero-knowledge” applies here as well. This slightly varied version of a zero-knowledge “Proof”, a SNARK, is much smaller in byte size, and can be verified quickly (meaning it is “Succinct”). It allows people to “verify” information without needing to communicate back & forth between the two parties, which explains how it is “non-interactive”, as it only needs one “proof” between a party proving themselves to a verifier. For “Arguments of Knowledge”, it refers to a party attempting to cheat the system, but just ends up having a low chance of doing so because they don’t have the knowledge (about the proof) or computing power to support it- as they aren’t aware of other private/important data in the SNARK to attack it.
A more recent version of zkProofs in action can be seen through zkSTARKs (Scalable Transparent Arguments of Knowledge).
The key difference here is that a STARK requires no “trusted setup” from verifiers initially (SNARKs do), they are more scalable (higher computation), and are quantum resistant.
Fraud Proof
A Fraud Proof is a newer concept, in comparison to zkProofs, that were created on the basis of the construction of plasma chains. The idea of a fraud proof is that we are always supposed to be “pessimistic” about the data that is compiled on the states that are published, that there is never anything correct with what is occurring, and that the data within them has been potentially tampered with- this is to help keep it secure from being attacked. Fraud proofs are very useful when it comes to increasing scalability, as in many cases they do not require significant computational resources. All of the information stored within the states of these proofs can be disputed during a period called a “Dispute Time Frame” where parties can argue against a potentially incorrect state (referring to the state of the Fraud Proof). If there are no fraud proofs submitted during this time frame, then it is just assumed that the state is correct, and it requires no “Dispute Time Frame”. Typically this time frame lasts about 1-2 weeks, but it can change according to the amount of security you want with the state (longer dispute times = more security of the state; shorter dispute times = better UX).
Fraud Proofs can be explained using Football (American Football 😉) as a real world example. While players on each team are playing, the coaches and referees make decisions based on what occurs on the field.
Imagine that the plays are transactions (transactions occurring on the Fraud Proof), the coaches are those making disputes on the state (referring to the state of the Fraud Proof), and the referees are the watchers/operators.
Let’s say a player catches a pass, which was a close catch (might have been an incomplete pass), and the referees call it a completion. The coach on the other team becomes upset and says, “This isn’t correct! I challenge that call! (similar to throwing a challenge flag)” This is an example of a dispute in a Fraud Proof. The referees, otherwise known as the operators of the Fraud Proof, are now being disputed about the call they made (or the state they shared). The time frame where the play is “under review” by the referees is similar to the dispute period in a Fraud Proof, and assuming the call was made properly, all is well! If not, then those who made the dispute properly are able to be rewarded (in the case of football, the call would be overturned).
That's it for Part One, please follow us for more updates on Ethereum scaling solutions as they are released. The next part of the series will be breaking down some of the specific solutions both on and off of Ethereum that you can research for scaling your Ethereum application..
1https://en.wikipedia.org/wiki/Zero-knowledge_proof#The_Ali_Baba_cave








