
Hi,
My name is Michael, and in the last post we covered how to:
Download historical Bitcoin data.
Read historical Bitcoin data from a CSV into a Pandas dataframe.
Create a time series of these data.
Plot the price of Bitcoin over its entire history.
In this post we'll further explore Pandas and learn how to:
- Combine two dataframes into one (BTC and ETH).
- Insert, rename, and drop specific columns from our dataframe.
- Reshape our dataframe by pivoting.
- Use Pandas to reveal trends between the data sets.
I'll assume you've gone through the last tutorial (only takes ten minutes) and we'll carry on from there. Let's get started!
1. The first thing we need is the historical price data of Bitcoin, which is easily found with a quick google search. I visited CryptoDataDownload.com and used the Coinbase exchange to get the daily historical prices for ETH. Save this as a comma-separated value (CSV) file and open up whatever you normally use to create and edit Python scripts. I will be using PyCharm, one of the best Integrated Development Environments (IDE) I've ever come across, which you can download the Community Edition for free from their website https://www.jetbrains.com/pycharm/.
Create a new script with a sensible name (I choose Plotting_Bitcoin_Part_2.py) and in the Bitcoin_Historical_Data directory save the ETH CSV file:

We'll begin the script by reading in the BTC and ETH data into dataframes:
# Folder name of the directory where the data is stored
folder_name = 'Bitcoin_Historical_Data'
# Name of the csv file to load into a pandas dataframe
btc_daily = 'Coinbase_BTCUSD_d.csv'
eth_daily = 'Coinbase_ETHUSD_d.csv'
# Join various path components
btc_daily_path = os.path.join(folder_name, btc_daily)
eth_daily_path = os.path.join(folder_name, eth_daily)
# Read in csv file data into pandas dataframe
btc_daily_df = pd.read_csv(btc_daily_path, skiprows=1)
eth_daily_df = pd.read_csv(eth_daily_path, skiprows=1)
# Inspect the first rows (5 by default) of the dataframes
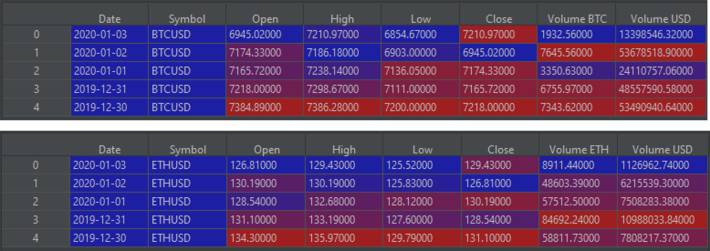
btc_daily_df.head()
eth_daily_df.head()
Okay, let's create a new column called 'COIN' and insert this into our dataframes. It will function similar to the 'Symbol' column, and hold information regarding the name of the coin the data belongs (BTC or ETH). Once we have this column, we can delete the symbol column:
# Add a new coin column to each dataframe
btc_daily_df.insert(0, 'COIN', 'BTC')
eth_daily_df.insert(0, 'COIN', 'ETH')
# delete the Symbol column from each dataframe
btc_daily_df.drop('Symbol', axis=1, inplace=True)
eth_daily_df.drop('Symbol', axis=1, inplace=True)
btc_daily_df.head()
eth_daily_df.head()
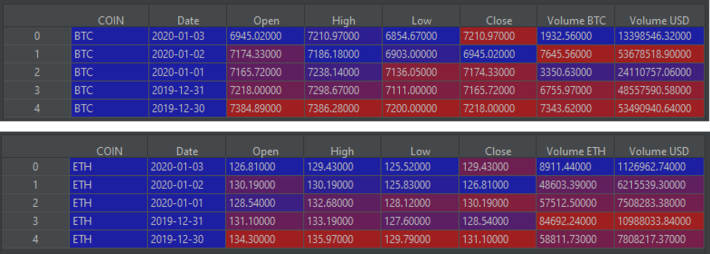
Great, we have our new column inserted into the '0' position of our dataframe, but 'COIN' doesn't match the format of the other column names. Let's rename 'COIN' to 'Coin':
btc_daily_df = btc_daily_df.rename({'COIN': 'Coin'}, axis=1)
eth_daily_df = eth_daily_df.rename({'COIN': 'Coin'}, axis=1)
You can check to see if this was renamed.
Our goal now is to make a new dataframe by joining (concatenating) our two separate dataframe, which we can do by using:
concatenated_df = pd.concat([btc_daily_df, eth_daily_df]).sort_index()
concatenated_df.head()
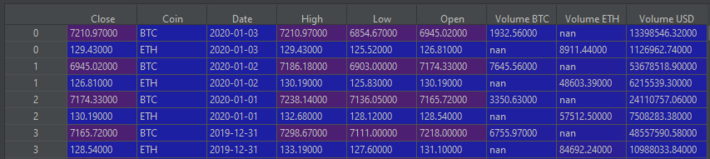
We now have a new dataframe that was built by joining both BTC and ETH dataframe. You'll notice that Pandas has filled in missing values with 'nan' (not a number) when data is missing.
At this point, we have done the hard work and can begin playing around with our data!
What we would like at this point is to have a new dataframe that is indexed by the 'Date' column, and has columns of 'Open' prices for each separate coin listed in 'Coin'.
open_df = concatenated_df.pivot(index='Date', columns='Coin', values='Open')
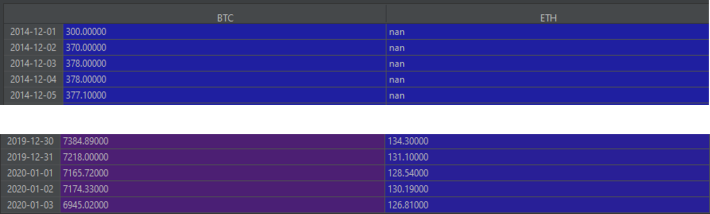
We've taken all the distinct values in the 'Coin' column and pivoted them into columns on our new dataframe with the 'Date' column as the index. The fact that Pandas makes doing such a complex operation so simple is one of the things I love about Pandas!
Notice that Pandas has once again filled in missing values with 'nan' (when BTC first came out, there was no ETH so naturally, these data will be missing).
With everything set up, we can now plot our data and see how they compare against each other:
open_df.plot(title='Bitcoin Opening Prices',
grid=True,
color=['red', 'blue']
)
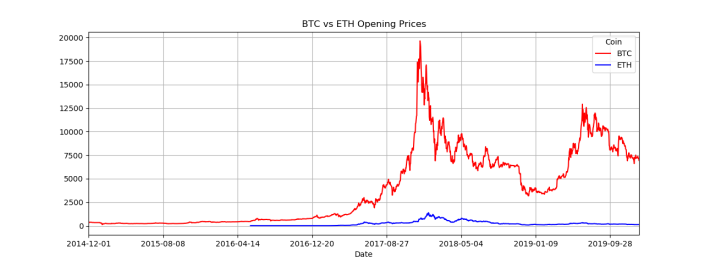
The opening prices are plotted, but because BTC values are so high compared to ETH it's hard to discern any noticeable pattern. One trick we can employ is to plot the prices on a logarithmic scale, which will bring them much closer together:
open_df.plot(title='Bitcoin Opening Prices',
grid=True,
color=['red', 'blue'],
logy=True
)
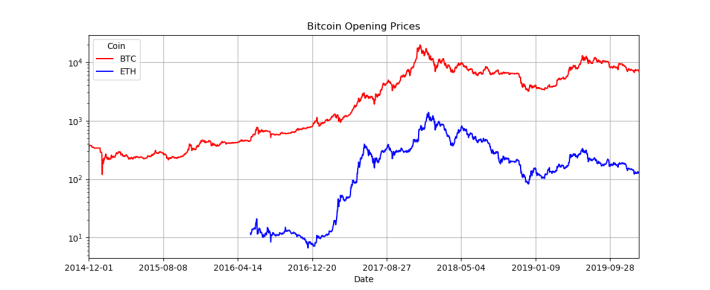
That is much better, and we can immediately see that the two coins are highly correlated: BTC goes up, ETH goes up; BTC goes down, ETH goes down. Perhaps BTC is a fairly good indicator for knowing when to buy or sell ETH.
We'll leave it there for now, but I hope you've enjoyed this tutorial and we'll pick up from here in the next one where we'll further explore reshaping our data to visualise and analyse it.
See you next time.








