
This blog is a piece of my mega-blog on my core k3s Kubernetes install. If you're here from that blog post, welcome! If not, be sure to check it out to see the bigger picture!
Longhorn is a block storage solution for bare-metal Kubernetes clusters. If you're self-hosting a Kubernetes server, this project is worth a look, and, when you get it installed, it is amazing. Admittedly, this was the hardest part of my entire cluster to get working, but I'm so glad I stuck with it. Having block storage is incredible, and this project ensures that my data is replicated across my clusters and handles mounting volumes to my Kubernetes pods no matter what server they are running on. Additionally, it handles backups. Hopefully, I never need these, but I have them!
Prepare the Nodes
Before you can install Longhorn into your cluster, you will need to prepare one or more nodes to function with Longhorn. Since the premise of Longhorn is to abstract away the disk / volumes for your Kubernetes cluster, it needs some tooling installed directly on each server.
Directly on each server, be sure to run the following:
sudo apt update \
&& sudo apt install open-iscsi -yopen-iscsi is a file system protocol Longhorn requires to function.
Next, we need to make your hard-drive shareable for Longhorn.
sudo mount --make-rshared /When you have this done, you will definitely want to run the pre-install Longhorn script to test that you have configured your cluster and underlying server infrastructure. This tool will really help you troubleshoot if you did not.
curl -sSfL https://raw.githubusercontent.com/longhorn/longhorn/v1.0.0/scripts/environment_check.sh | bash
You must run this command from a computer with kubectl access to your cluster.
Installing
This tutorial will be installing Longhorn with Helm, so here is an example values yaml:
csi:
kubeletRootDir: /var/lib/kubelet
defaultSettings:
replicaSoftAntiAffinity: true
replicaZoneSoftAntiAffinity: true
createDefaultDiskLabeledNodes: true
defaultReplicaCount: 2
defaultLonghornStaticStorageClass: longhorn-static-storageclass
guaranteedEngineCPU: 0.10
As you can see, I don't configure a whole lot. Here's my best breakdown of these values
- The
kubletRootDiris specific to k3s, so different Kubernetes installations could require something different. - The replica properties are because I'm running with a small cluster, in fact, when I started I had a single node, so, even though Longhorn replicates data, it needed to know it was okay to replicate the data on the same HD and node.
- I attempted to allow Longhorn to create default disks, but in practice this doesn't work for me. Instead, I use the Longhorn UI to manage all my disks and volumes.
- The default replica count tells Longhorn that, by default, I want 2 copies of each volume it creates.
- The default static storage class is just the name for the Kubernetes Storage class made by Longhorn
- Do your own calculations on
guaranteedEngineCPU, but this is the number of cores allocated on each server for Longhorn. If you do something with intensive I/O you may want a higher value. I still wonder if I should increase this on my home server, but this is not something you can change with any volumes mounted, so I would need to stop my whole cluster to increase this.
Longhorn is a complicated tool that serves an important purpose for bare metal Kubernetes installations, if you need more information, you'll definitely want to read the docs.
Installing
With our values configured, we're ready to install - just a word of note, this install took a long time. Longhorn brings a ton of moving parts with it, and in fact, I struggled with this for hours. I really hope I've nailed down everything to get you up and running, since this is an important piece to your own awesome home server, but, if I didn't, please drop a comment below or if you think you've found a bug, raise it with the Longhorn team under the correct component repository.
# The first time
helm repo add longhorn https://charts.longhorn.io
# Every time
helm repo update
helm upgrade --install -n longhorn-system -f longhorn-io-values.yaml longhorn longhorn/longhornOn a 3 node Kubernetes server, here's an idea on the size of this install by glancing at the pods this has created on my k3s cluster:
> kubectl get all -n longhorn-system
NAME READY STATUS RESTARTS AGE
pod/longhorn-driver-deployer-6dcf6cb6c4-w7m67 1/1 Running 2 105d
pod/longhorn-ui-5576b69d6d-pvf9h 1/1 Running 5 105d
pod/instance-manager-e-62d2faa6 1/1 Running 0 64d
pod/instance-manager-r-9fb7ddf5 1/1 Running 0 64d
pod/csi-provisioner-5c9dfb6446-jsqlk 1/1 Running 1 64d
pod/csi-snapshotter-96bfff7c9-jldm5 1/1 Running 0 64d
pod/csi-resizer-54d484bf8-26tqw 1/1 Running 1 64d
pod/csi-snapshotter-96bfff7c9-55sn8 1/1 Running 0 64d
pod/csi-snapshotter-96bfff7c9-vp7cq 1/1 Running 0 64d
pod/csi-attacher-5dcdcd5984-bxn9f 1/1 Running 1 64d
pod/csi-attacher-5dcdcd5984-lcmvg 1/1 Running 1 64d
pod/csi-provisioner-5c9dfb6446-kxh5g 1/1 Running 1 64d
pod/csi-resizer-54d484bf8-bbw74 1/1 Running 1 64d
pod/csi-provisioner-5c9dfb6446-ft9jr 1/1 Running 1 64d
pod/csi-resizer-54d484bf8-nvnvn 1/1 Running 1 64d
pod/csi-attacher-5dcdcd5984-56cfh 1/1 Running 1 64d
pod/longhorn-csi-plugin-s8gf4 2/2 Running 0 64d
pod/longhorn-manager-l2mth 1/1 Running 2 102d
pod/engine-image-ei-cf743f9c-89hp5 1/1 Running 2 102d
pod/longhorn-csi-plugin-whz2q 2/2 Running 0 55d
pod/longhorn-manager-pzbtw 1/1 Running 0 55d
pod/engine-image-ei-cf743f9c-dhd64 1/1 Running 0 55d
pod/instance-manager-e-544b4494 1/1 Running 0 55d
pod/instance-manager-r-777af485 1/1 Running 0 55d
pod/longhorn-csi-plugin-sxk7k 2/2 Running 10 63d
pod/instance-manager-e-9d1895ec 1/1 Running 0 52d
pod/instance-manager-r-d6456a38 1/1 Running 0 52d
pod/engine-image-ei-cf743f9c-jd2sh 1/1 Running 5 63d
pod/longhorn-manager-2l24h 1/1 Running 5 63dConfiguring
Once everything comes up, you will need to continue setup on the Longhorn Dashboard. For this part, the MetalLB tutorial comes in handy, and I have configured an external IP address for my Longhorn dashboard + mDNS name, so I am able to open it up at http://longhorn.local/
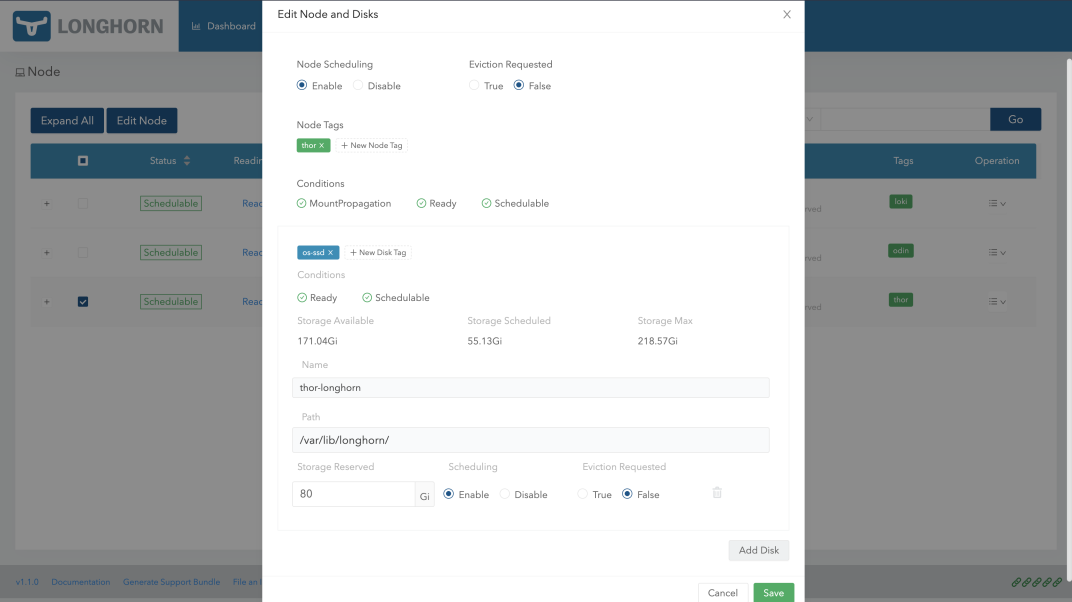
The first place you'll want to go is to the Node tab - you'll want to edit each node in your cluster and add a disk on each node for Longhorn to schedule. Notice that, on my 240gb hard drives, I left 80gb reserved for the OS. I recommend leaving at least 80gb reserved per server for OS critical files.
As you create more volumes in your cluster, the Volume tab is useful for managing backups (after you have picked a backup location).
The highlighted button will bring up a simple cron editor for you to schedule backups of your data.

Most importantly, you will want to configure a backup location for your data. I am running an NFS server on a Raspberry Pi, so my backups go there.

And that's it! If you've made it this far and have Longhorn installed and operational, what this has enabled you do use is the PersistentVolumeClaim in your Kubernetes cluster. A PVC lets you request a volume of any disk size, and, if you have the room, your Kubernetes cluster will issue you a volume from your default storage class. This tutorial was to allow us to make Longhorn available to our Kubernetes cluster, and, if you're following along with the master k3s installation guide, Longhorn is our only and therefore default storage provider. This allows us to have block storage for our at home Kubernetes install, which is simply awesome!
Be sure to check out the final piece of this install, which is Traefik for ingress and SSL certs. These SSL certs will be your first volume created by Longhorn!








