
Researchers working on mini versions of the full scale AI models that use fewer resources and are super-efficient
One of the many ways that the researchers have been working to fight the ever-increasing threat of deepfakes is to develop AI tools that can spot such instances and root them out. Of course, for them to be successful at this, they need to know how these deepfakes are created in the first place.
While these intelligent systems are a good solution to countering the deepfakes problem, they come with the risk of producing yet another tool that can create more deepfakes. Secondly, these giant programs are too resource-heavy and computationally expensive. This could concentrate Artificial Intelligence research into the hands of a few tech giants.
Last year, Google researchers unveiled an AI system called Bert, which went on to pass the long-held reading-comprehension benchmark in the field. However, training this large model on 340 million data parameters was the equivalent of powering a U.S household for 50 days. The carbon footprint of such a system as calculated by the University of Massachusetts, Amherst was equivalent to a round-trip flight between New York and San Francisco.
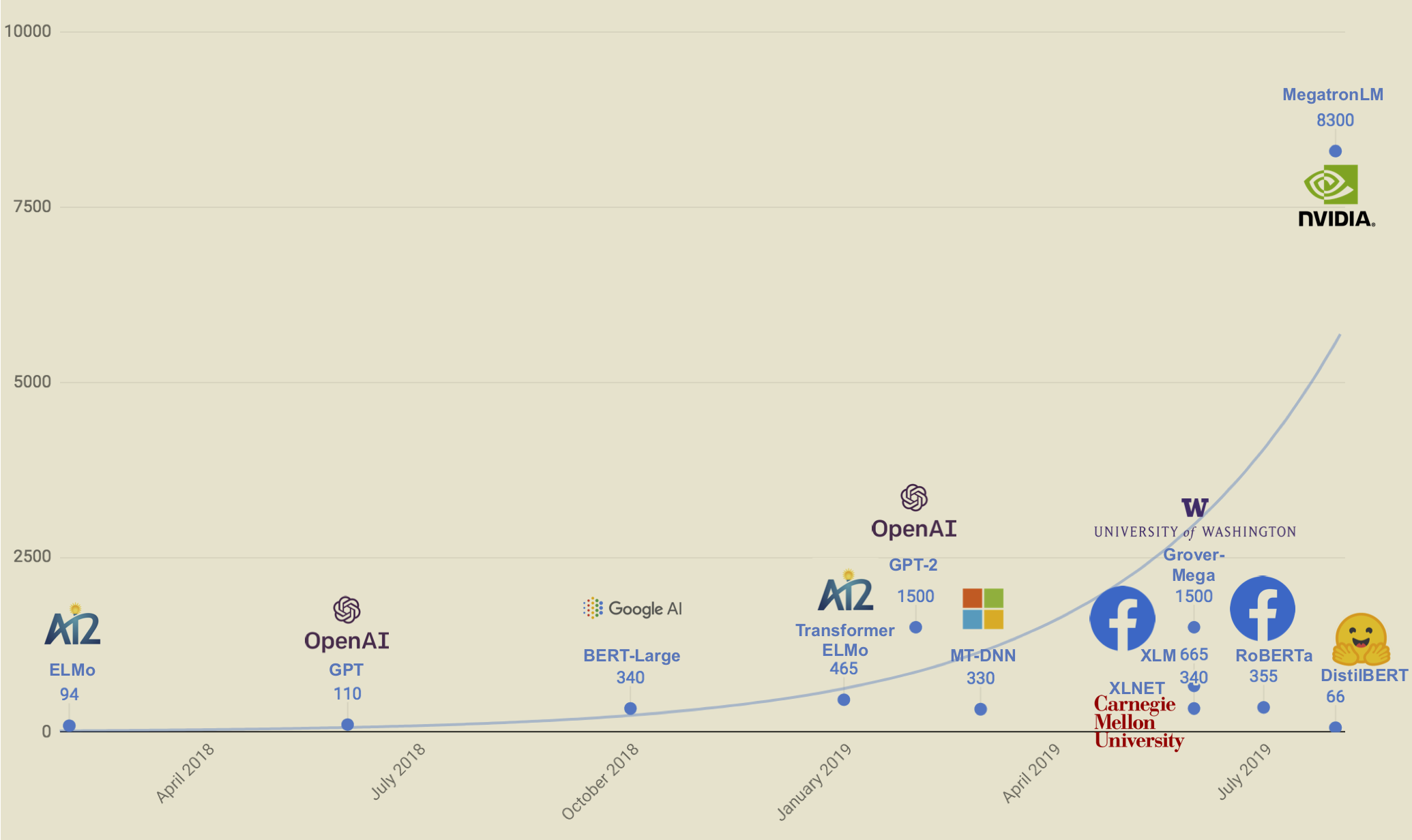
Image Credit — https://medium.com/huggingface/distilbert-8cf3380435b5
OpenAI topped Bert with its own AI tool dubbed GPT2 , which mimicked the writing style of humans with high accuracy. It used an astonishing 1.5 billion parameters to train its model. This doesn’t stop there — MegatronLM, the latest and largest model from Nvidia trains on 8.3 billion parameters(chart above). The trend is clear.
To address the issues of heavy resource utilization & climate toll, researchers have been actively pursuing an option where they can shrink these AI’s in size, thus not only reducing their resource-intensive nature but at the same time making them more efficient.
Two new research papers released recently, have come up with models that might be able to accomplish this. The first one is from researchers at Huawei Noah’s Ark Lab called TinyBERT (figure below). They presented a theoretical model, which is one-seventh the size of the original BERT model with 10x the speed. TinyBERT was as capable of the same language understanding as the original.
The second proposal came from the Google researchers themselves producing a tiny version of their AI predecessor by a factor of 60. However, this much tinnier version than Huawei’s had to sacrifice a little on the language understanding capability.
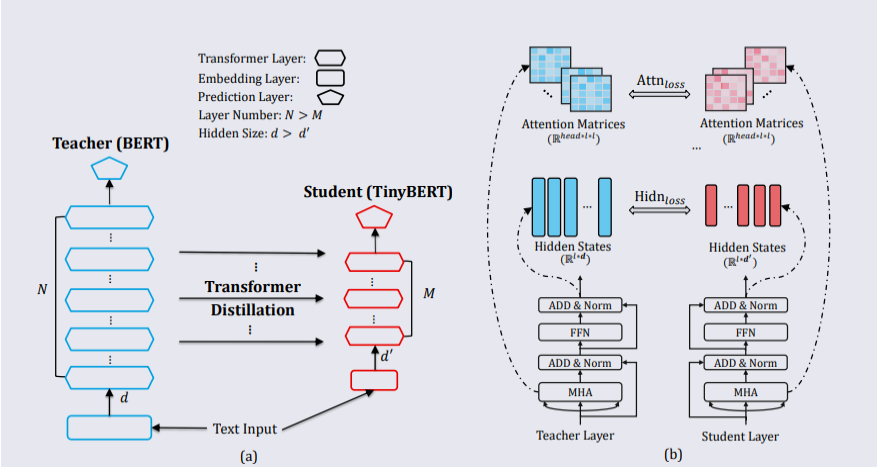
TinyBERT — Huawei Research Paper
Both papers work on a common compression technique known as knowledge distillation to build the smaller versions of the full-scale AI models. The “teacher” AI trains the shrunk “student” AI to produce the same result as the former given a set of inputs.
These tiny AI’s can eventually be used in consumer devices like smartphones for natural language processing in digital assistants like Siri, Alexa & Google Assistant. Without the need to send consumer data to the cloud, this would eventually improve processing speed & privacy.
Just a quick word, before I let you go, about my most favorite area of AI application — in the healthcare industry. Chip giant Intel and Brown University have started work on a DARPA-backed Intelligent Spine Interface project that aims to uses AI technology to restore movement and bladder control for patients paralyzed by severe spinal cord injuries. The two-year project will be utilizing open-source AI software like nGraph & Intel AI accelerator hardware for the purpose.
How excited or worried are you about AI’s advancements?








