

Last Friday, on August 7th, Presearch organized a community Ask-Me-Anything event with the recently hired CTO, Trey Grainger. It was a great session and we’re happy to share a summary for all of you who missed the event.
Introduction
Marco: So, Trey Grainger is Presearch’s new CTO! Trey has been involved with Presearch as an Advisor since July 2017, and he just joined Presearch as our new CTO (Chief Technology Officer) at the end of June.
Prior to joining Presearch, Trey played key roles at Lucidworks (an AI-powered search engine company), first as as SVP of Engineering and then as Chief Algorithms Officer, where he led both their commercial and open source software development teams. Lucidworks delivers AI-powered search solutions that are built upon the leading Apache Lucene and Apache Solr open source projects, which power search for thousands of companies worldwide. Lucidworks customers include Reddit, Uber, and many of the world’s largest brands.
In addition to his work with Lucidworks, Trey is the author of the books AI-Powered Search and Solr in Action, is an advisor to several organizations through his consulting company (Searchkernel), and is a regular speaker at conferences, published researcher on search technology, and contributor within the open source community.
As the new CTO for Presearch, Trey works with the development team responsible for the current Presearch platform that now supports more than 1.5 million registered users, and he is currently focused on transitioning Presearch from from it’s first phase (Launch & Establishing Product Market Fit) to its second phase (Sustainability & Decentralized Search Engine), which is well underway with the recent announcement regarding the upcoming Presearch nodes release.
As most of you know, Presearch just released our new Vision Paper (whitepaper 2.0) a week ago, including 65 pages of details regarding everything from the decentralized search engine architecture, to tokenomics around the growing role of the PRE token, to everything in between.
Trey: Wow, nice long introduction there… thanks Marco.
I’m extremely excited to be here (at Presearch) and also here (at this AMA) to talk with the community and answer questions today!
Questions & Answers
Question 1, Adarsh: Hi, the node concept in Presearch looks something similar to Tor. Maybe Presearch can provide the same anonymity as Tor in the near future. My question is: Tor only leaks information at the exit node (I’m not sure), while the connections in between are highly encrypted layer by layer with no user control, whereas Presearch allows user to control the node. This means any guy with malicious intent can leak or read information. How is Presearch is going to tackle this issue? Also Tor tends to be slower. What about Presearch?
Trey: So Tor is focused on anonymizing the source of internet traffic. Since web requests are traceable, it does this by making multiple internal hops, so that only the starting node actually knows the source of the traffic, and the exit node know the final request being made. In the Presearch world, we have the same need to keep the “source” node’s IP address and other personally identifiable information private, and we need to make sure the “exit node” does not know who any private information about the person running the search.
Unfortunately it IS possible for some queries to reveal private information, however (such as if you search for an address or a person’s name). As such, we will have two mechanisms to protect privacy:
1) Node Gateways, which receive incoming requests and anonymize them before passing onto nodes
2) Node validators, which run on the nodes and communicate constantly with the node gateways to ensure that the Presearch node software hasn’t been tampered with (i.e. to log user queries)
This way, the nodes NEVER know who the person was based upon their location or IP, and they also can’t log info to try to gain access to the queries. If they somehow manages to log a query and bypass our security, however, they at least don’t know where the query originated from, and the node software will kick any node off the network when it detects someone trying to tamper with the node software
Question 2, Emmadags: How do you intend going about implementing sending PRE between accounts without incurring the Ethereum or GAS network fee?
Trey: Great question. As many of you may know, ETH gas costs can fluctuate significantly. Just last week I saw them spike over $5. This is infeasible for small transactions, so we are planning on a feature to enable PRE token holders who hold PRE in their Presearch accounts to send between accounts by entering the e-mail address of another PRE holder.
This will allow an account-to-account transfer to occur on the blockchain directly, you can still do that, of course, but then you’d have to pay the current ETH gas cost.
Question 3, Ibrahim: My first question is regarding the image search on Presearch, there seems to be limited access to some high-end which makes it repeat almost what it has shown initially. Any upgrade regarding that?.
Trey: Hi Ibrahim, I believe you’re talking about the image search on engine.presearch.org (which is in beta). When we roll out the new nodes-based-search, we are replacing that search entirely with something much better. We are aware of the image “looping” issue when you page through images, and it will be going away once the nodes launch.
The nodes-based search user experience is substantially better than the current engine.presearch.org results, so our attention is completely focused on that for now.
Question 4, VyachCrypto: Could you tell us what is the roadmap for the second half of 2020 that would make the long term investors excited about the project?
Trey:
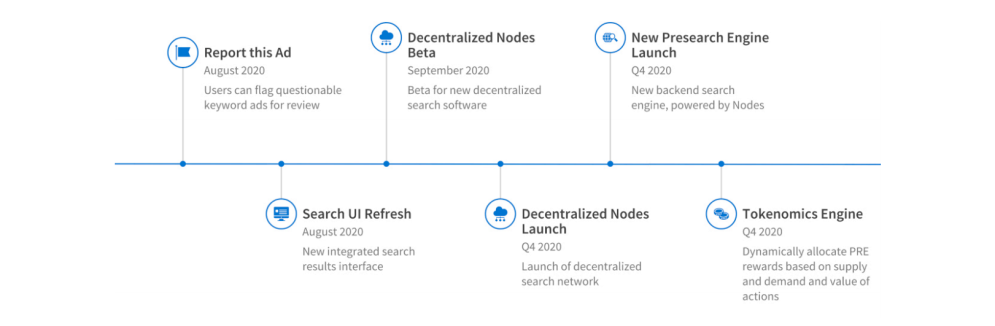
Marco: Thanks Trey, and remember — a full roadmap + marketing roadmap can be found in the Vision Paper.
Trey: If you have questions about any of the specific elements, here, let me know. Our primary focus is on the launch of the distributed nodes, the new presearch engine results and experience, and getting the Tokenomics engine in place, which are huge milestones. The roadmap for 2021 is also outlined in the whitepaper, as @TMod_Marco just referenced.
Question 5, Justin: Will search providers (including default and highlighted) be specific or different based on the country of the user? Different countries have more/less popular websites. Perhaps search providers should pay separate fees to be global, continent or only specific countries.
Trey: At the moment, we have a long list of providers (128, if I remember correctly), plus the ability for any Presearch user to add their own custom providers. The default providers list is currently global, but we have future plans to make this all community-driven.
If a provider wants to be added to the list, yes, they can pay a listing fee, and we are requiring them to also stake tokens. If they want to be considered for the default providers list, the listing fee will be higher, and they will also need to maintain a higher stake.
The level of the stake will determine placement in the list, HOWEVER, we also want the community to be able to stake for their favorite providers, so that the community can also help influence the relative value and order of providers.
This is not implemented yet, but it is one example where we want the community to be able to drive how the engine works.
We don’t have plans currently to localize the providers in the default bar based upon country or language, but that is a great idea and I’ll take it back to the team for us to consider when we start to add some of this in! Thanks for the suggestion!
Question 6, VyachCrypto: Every project has its own position in the market, how does Presearch plan to stay competitive compared to other projects?
Trey: Good question. Presearch has multiple value propositions — Privacy is a key one. Rewards is another key one. Usefulness and ability to quickly navigate to other search providers is also helpful. Alone, however, I don’t think those are sufficient to make Presearch the best search engine in the world (obviously our goal 💪). DuckDuckGo is pretty good on privacy. Bing has rewards, etc.
The decentralization and community control is really, in my opinion, the long-term driver of value. Making it so there is not a large, for-profit corporation that controls access to information and profits off of users to enrich shareholders at the expense of the users is key. Giving software engineers, data scientists, and subject matter experts around the world the ability to contribute code and expertise to make the engine better — and then rewarding them for the value they provide with PRE tokens, can help us build Presearch leveraging tens of thousands or hundreds of thousands of people all around the world toward a shared goal — to create an open, community-powered, and decentralized search engine that is built by and for the community, and leveraging the diverse expertise of all who contribute to it.
Privacy and search rewards are important, but it is this vision of creating an open, decentralized, community-powered engine that will ultimately by Presearch’s distinguishing value proposition IMHO.
Question 7, Jan: Is it possible to run more than one node from one IP address?
What requirements are there for a PC to drive nodes (RAM, HD) and how do you validate PC´s?
Trey: Great question. We stated in the Vision Paper that you can only run one node per IP address, and this is the case, at least for now. There are multiple node roles that search nodes will ultimately be able to take on (Federating, Crawling, Indexing, Serving, etc.). The first node role we are implementing is the Federating one, which needs to reach out to other engines to pull in content. If the same IP address is used to make too many requests, this can lead to all of the nodes under that IP address getting blocked, therefore we define a “node” as the software coming from one, publicly-facing IP address.
In the future, as other node roles are implemented, we may remove this restriction, but our entire tokenomics model is built around the idea that there will only be one IP address per node, so this is a hard and fast rule for now.
That being said, you can definitely run multiple nodes per account, as long as you have multiple IP addresses. If you are running in a cloud provider, for example, you could spin up as many as you want. : )
Question 8, Adarsh: Does presearch plans to construct their own data centers or depend on the community using nodes?
Trey: We do not plan to construct our own data centers. Our model is to pay Node Rewards to those running the Presearch node software to incentivize others to provide server/network capacity. Presearch will be operating our own infrastructure (cloud-based) in the early days to ensure that the network has enough resources to operate (we’ll autoscale up and down as needed), but once the network is sufficiently large then we don’t expect we’ll need these.
At some point it is likely that some node operators will provide their own data centers and stake PRE to reserve a certain amount of capacity (and corresponding Node Rewards that they will earn). This is the model we want — decentralization of the network, not a centralized network run by the Presearch organization.
Question 9, Jan: How does searches “choose” between different nodes? Is it random or will nodes staked with higher get more searches? What significance does geography have for which node is assigned a search?
Trey: Great question. Going back to the different “node roles” (Federating, Coordinating, Indexing, Serving, Crawling, etc.), ultimately different nodes will have different characteristics (in terms of geographical location, latency, disk space, CPU, memory, uptime/reliability, etc.), and the network will choose the nodes based upon their capacity. Node Staking allows certain nodes to claim the right to provide a certain amount of capacity (whenever the network has too much capacity), but otherwise node roles will assigned purely based upon which nodes “server profile” best meets the needs of that role.
For our first release, focused on the Federation role, we will try to allocate traffic roughly evenly across all the nodes, but there will be a bias toward more reliable nodes and those with lower latency, since those provide a better search experience.
Over time, as more node roles are released, the way the nodes are chosen will get more complicated, but will still follow those same principles of 1) choosing the nodes best suited for a role, and 2) preferring nodes with a higher stake when there is too much capacity.
Question 10, Chain lol: How secure is that locked tokens in ERC-20 contract from hacking ? and if something was terribly wrong with this smart contract ?
Trey: The ERC20 contract was audited by smart contract experts prior the token being created in 2017. We feel confident in it, and the contract has never been hacked. However, there are vulnerabilities that could come to light in the future with the ERC20 standard, the Ethereum network, or even Presearch’s own IT systems that we can’t predict. If something went terribly wrong with the smart contract then, like many other projects have done, we do have the fallback option to do a token swap. In this case, we could blacklist the “hacker’s” wallet and ensure that everyone else received the swapped token and that it coninued to provide the same utility within the Presearch ecosystem.
It is worth pointing out that the PRE token isn’t running on its own blockchain. It is a utility token that is used as the store of value and mechanism for transferring value within the Presearch platform. We are committed to the token being that store of value, but if we needed to swap the token a some point either due to a hack (unlikely) or due to technological innovations in the smart contract specifications (such as to enable uniswap or new defi or smart contract applications), then we could.
Question 11, Emmadags: Will intending advertisers on the platform pay with PRE or other standard Fiat currency? Or there will be room for both forms of payment?
Trey: Both. We need both Fiat and PRE to operate. By receiving Fiat money, we can use that to buy back PRE off the open market and reduce outstanding supply, and by receiving PRE, we are also reducing outstanding supply. In the Vision Paper, we talk about how we plan to use the incoming revenue (whether in PRE or Fiat), but ultimately regardless of which form the payment is received in, the value gets pushed back into the token.
So it doesn’t really matter whether we receive PRE or Fiat revenue, as we’ll ultimately need a balance of both, and the net outcome will be that excess Fiat gets converted into PRE and that excess PRE would have to be sold to get Fiat. So a good balance is preferred.
Question 12, MAD TN: Hi Trey, thanks for your time today. Quick question, how do you keep up with all the latest technology whether its search, cryptocurrency related etc.? Do you have a go to source(s)? Also, with technology changing so frequently will the vision paper be updated periodically as it evolves, if so, how often?
Trey: Yes, I’m not sure on the exact timeline for updates but we do expect to update it more frequently. This update from the original whitepaper (circa 2017) to the new Vision Paper was obviously a substantial update, as the original was focused on selling the vision (prior to building), whereas now much as been built and we’re transitioning to a phase where we focus much more on the decentralized search engine and tokenomics of the whole ecosystem.
I expect we’ll have more incremental updates to the Vision Paper going forward as the roadmap evolves. From the whitepaper we went from 1.0 to 2.0 after three years. I expect we’ll have a 2.1, 2.2, 2.3, etc. this time.
Question 13, Adarsh: Have you started working on NLP algorithms for better search experience or its kept on later part(2021,2022).
Trey: I’ll start the answer to that question with saying NLP algorithms, relevance ranking, AI-powered search, etc. are very much my domain of expertise. I’m writing a book on it all, in fact: http://aiPoweredSearch.com.
That said, right now our focus is much more on building out the decentralized search architecture. The more sophisticated algorithms will come, but our real goal is to enable the community to contribute code and algorithms (and then measure their value and reward those community accordingly with PRE), as opposed to use just building everything ourselves. That’s how we ultimately scale our model and enable the best and brightest people in the world to help propel Presearch to success.
So we’ll definitely do more sophisticated NLP work in the future, but it is not our main focus right now.
Question 14, Moises: What will be the hardware level requirements of the pc to run a node?
Trey: Different kinds of servers will work better for powering these different use cases. For example:
1) Coordinating will work best on nodes with low network latency, high network bandwidth, and high memory (disk space unimportant, CPU useful, but can vary).
2) Federating will work best on nodes with: low networking latency (CPU, memory, and disk space unimportant; high bandwidth preferred).
3) Serving will work best on nodes with high memory, high uptime, and low network latency (CPU and disk space useful, but can vary).
4) Crawling will work best on nodes with: high disk space, high network bandwidth (CPU, memory, network latency, and uptime unimportant).
5) Indexing will work best on nodes with: high disk space, high network bandwidth, low network latency, and reasonable CPU, memory, and uptime.
For the first release, we’ll be focused on the “Federating” role, which means that Presesarch will initially aim for a network of as many nodes as possible, provided as cheaply as possible, so long as their network latency is low.
When Presearch later adds Serving and Coordinating operations (enabling the Presearch search index to be decentralized), this will introduce the need for different and more powerful servers to join the network.
When Crawling becomes fully decentralized and supported by nodes, the capacity of the network to crawl the web and refresh data will then be tied directly to the size of the network and its growth.
In otherwords, a cheap raspberry pi or heroku instance is likely to maximize your cost/rewards ratio for the first release. This will change over time as new node roles are rolled out.
Question 15, Jhonathan: Can you explain the difference between capacity and utilization on rewards calculation on the Presearch platform?
Trey: Good question. Yes, in the vision paper, we outlined the formula for calculating Node Rewards. In that calculation, we showed that rewards are base on essentially three factors, 1) Capacity provided, 2) utilization of that capacity, and 3) reliability of the node
Capacity provided is based upon the servers being available, an based upon the level of Node Staking the node operator provides. The higher the stake, the more capacity they can “reserve” to ensure stability of their node rewards. The utilization, on the other hand, is based upon number of operations that actually occur on the node.
To receive rewards for operating a node, you must stake at least 1,000 PRE, but the more you stake, the more right you claim to provide capacity within the network (and hence you also claim access to the corresponding rewards for providing that capacity). This is to incentivize infrastructure providers to allocate sizable capacity without worrying about too many other nodes joining the network and them losing money.
Essentially, there is value to the Presearch network in always having capacity available, as well as for utilization of that capacity, so we divide the rewards along those lines. This leads to a situation where everyone wins — people running nodes with a low stake get most of their rewards from utilization, whereas infrastructure providers get a sizable portion of their rewards for providing stable capacity. This means more staking, more nodes, and more predictability, generally a win-win for everyone.
Question 16, I AM | DIGIBYTE: What role does the community play in the Presearch? What have you done and will do to attract people to join Presearch and build a prosperous community?
Colin Pape (CEO, Founder): The community is super important to Presearch! You are why we are building the project!
In the short term, anyone can build packages: https://github.com/PresearchOfficial/presearch-packages and provide us with feedback on the product and our strategy via Telegram.
We have a group called the PRE Corps that includes many of our most active promoters.
And then as we go, community members will be able to run nodes to power the network and earn PRE.
I’ve been researching a ‘task pool’ concept that would be similar to a bounty platform and enable members to earn PRE for doing jobs the community comes up with and funds, with the project being able to add incentive multipliers.
Lots of awesome stuff on the horizon!
— — — — — — — — — — — — — — — — — —
With that exciting and final answer, the ‘official’ Ask-Me-Anything session ended. We loved seeing the enthusiasm of our community members and Trey decided to answer various more questions afterwards.
We’re looking forward to having another community AMA very soon! Stay tuned! ;) We’re looking forward to everything that’s coming up and thank you for being a part of this journey.
The winners of this AMA are:
- Adarshj322
- Justin775
- Jan Mølholm
Please send a private message to TMod_Marco to claim your prize.








