
In the current era of knowledge and information economy data is a new commodity (like unrefined gold). From data we can extract insights, knowledge, etc. which helps us to develop new inventions, products, services, etc. But if data is not clean we run into the “garbage in garbage out” problem. To solve this problem we need to clean our data.
Most often we encounter two type of problems with data. The first problem is missing data and the second problem is existence of outliers (data that is outside of boundaries where the majority of data is).
To solve these problems data experts need to understand business problems and data and make a decision about how to deal with the problems (delete, modify, use the data as is).
To solve the problem of missing data two approaches are used. The first approach is to delete data with missed values and the second approach is to replace missed values with some calculated new values. In some rare cases a decision may be made that data should be used as is without any modifications.
Let us consider how it can be done.
First we load the required libraries and data.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
url=’https://www.ispreport.xyz/data/test.csv’
df=pd.read_csv(url)
To find empty values we need to run the following commands
#count na in each column
z=df.isnull().sum()
for i in z.index:
if (z[i]>0):
print("column :",i,"has ",z[i],"na")
#count na in each row
for i in range(len(df.index)):
x=df.iloc[i].isnull().sum()
if (x>0):
print("row :",i,"has ",x,"na")
The result is shown below.
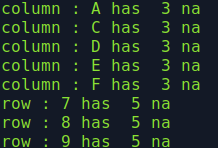
If you need to delete rows with value na you can use the following commands:
df.dropna() drop all rows where there is at least one na
df.dropna(axis=0 how=”all”) drop rows where all data na
df.dropna(axis=1) drop all columns where there is at least one na
df.dropna(axis=1 how=”all”) drop columns where all data na
To find duplicates we use the following command:
df.duplicated()
The result is shown below:

We see that there are duplicates with 4-th rows.
To remove duplicates we use the following command:
df.drop_duplicates(inplace=True)
Filling in missing data (imputation)
To fill na with a value x use the following command:
df.fillna(x, inplace=True)
To fill na with the mean use the following commands
from sklearn.impute import SimpleImputer as sm
im=sm(missing_values=np.nan,strategy="mean")
im=im.fit(df)
df=im.transform(df)
The simple way to do this is to use the following command:
df.fillna(df.mean(),inplace=True)
Finding outliers
Outliers are values that strongly different from majority of other data. A simple way to find outliers is to use histograms on columns.
To build a histogram for column A use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.A.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
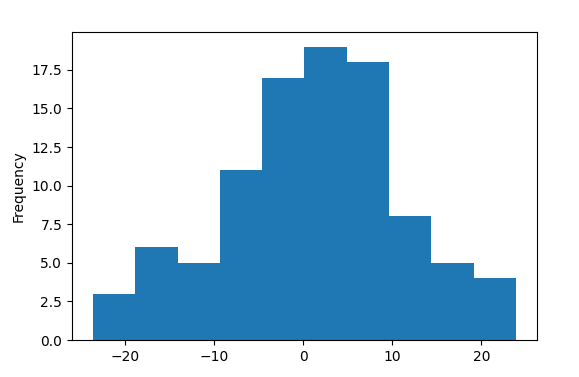
As we see there are no outliers in column A.
To build a histogram for column B use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.B.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
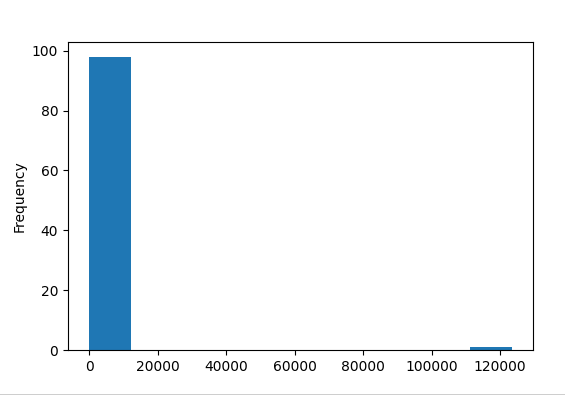
As we see there are outliers with values over 120,000 in column B.
To build a histogram for column C use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.C.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
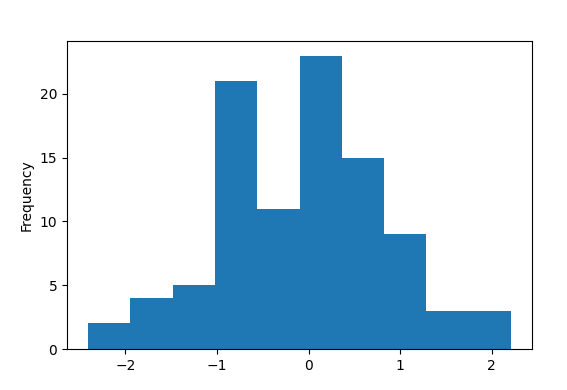
As we see there are no outliers in column C.
To build a histogram for column D use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.D.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
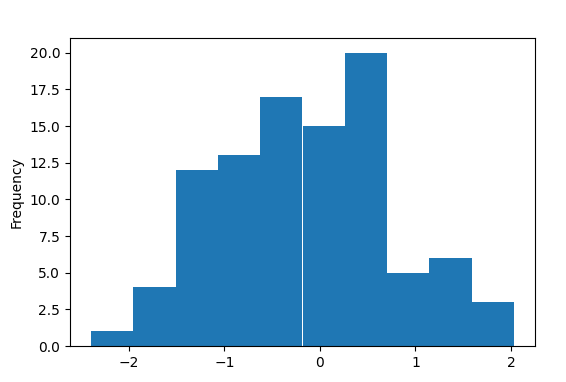
To build a histogram for column E use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.E.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
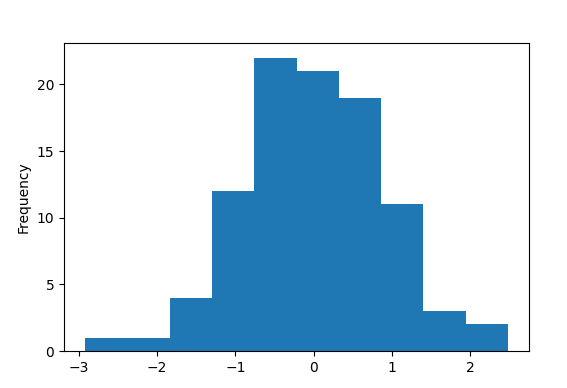
As we see there are no outliers in column E.
To build a histogram for column F use the following commands:
fig,ax=plt.subplots(figsize=(6,4))
df.F.plot(kind="hist",ax=ax)
plt.show()
The result is shown below.
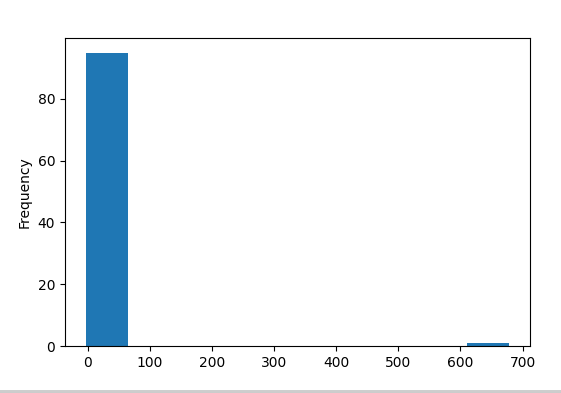
As we see there are outliers with values over 600 in column F.
To find these outliers we need to run these commands:
print('outlier in B')
o=df.loc[df.B>1000]
print(o)
print('outlier in F')
o=df.loc[df.F>100]
print(o)
The result is shown below.

As we see there are outliers in the first row of column B and the tenth row of column F.
The decision about how to deal with outliers usually are made on meetings where all stake holders are present (business, marketing, technology, etc.)








