
You are reading an excerpt from our free but shortened abridged report! While still packed with incredible research and data, for just $20/month you can upgrade to our FULL library of 50+ reports (including this one) and complete industry-leading analysis on the top crypto assets.

Becoming a Premium member means enjoying all the perks of a Basic membership PLUS:
- Full-length CORE Reports: More technical, in-depth research, actionable insights, and potential market alpha for serious crypto users
- Early access to future CORE ratings: Being early is sometimes just as important as being right!
- Premium Member CORE+ Reports: Coverage on the top issues pertaining to crypto users like bridge security, layer two solutions, DeFi plays, and more
- CORE report Audio playback: Don’t want to read? No problem! Listen on the go.
Overview of Artificial Intelligence (AI) and Machine Learning (ML)
Artificial Intelligence (AI) is the attempt to mirror human intelligence/cognitive functions within a machine. By harnessing the power of algorithms and sophisticated data analysis, these machines garner the ability to learn from past experiences, adapt to novel scenarios, and execute tasks that traditionally necessitate human insight.
Machine learning, an integral subset of artificial intelligence, concentrates on crafting algorithms and statistical frameworks that empower computers to extract insights and form decisions anchored in data. At its essence, ML revolves around facilitating machines to recognize patterns, much akin to human learning, albeit at a vastly accelerated pace.
The process of ML is fairly straightforward. When provided with fundamental guidelines, an ML system can be devised to identify trends or forecast outcomes based on specific data. Various methods, including supervised, unsupervised, and reinforcement learning, are used to develop
these models. Essentially, these approaches focus on refining a sequence of weights and structures, optimizing them to draw accurate conclusions from the given data. In order to do so, ML hinges on three cardinal components.
● Training Data: Think of training data as the foundational bedrock of ML. It's this data that the algorithm harnesses to form predictions or categorize fresh data. Varied in nature, training data can encompass visuals, textual content, numerical metrics, or even an intricate blend of these facets.
● Model Architecture: This encapsulates the blueprint of a machine learning model. Envisage it as the skeletal structure that determines the design, the diversity and quantum of layers, the activation mechanisms, and the intricate interlinkages between nodes or artificial neurons. Tailoring this architecture hinges on the unique challenges posed by the problem statement and the nature of the data at hand.
● Model Parameters: Delving deeper, we encounter model parameters - the crux of the learning process. These are the dynamic values that a model imbibes during its training trajectory. Adjusted in a continuous loop, these parameters are finetuned through optimization algorithms to bridge the chasm between projected outcomes and actual results.
Large Language Models (LLM)
A language model is a specialized machine-learning tool designed to generate and predict coherent language patterns. A simple illustration of this is the autocomplete function, which many users encounter daily. Large Language Models (LLMs) stand at the forefront of advancements in natural language processing (NLP). Characterized by their extensive training on vast datasets, LLMs are aptly named for their expansive nature. These models are adept at a wide spectrum of tasks, from recognizing and translating text to predicting or even generating content.
At their essence, LLMs can be likened to neural networks (NNs), sophisticated computing systems modeled after the intricacies of the human brain. These networks operate using an intricate arrangement of nodes, layered in a manner reminiscent of neuronal configurations.
At their core, language models determine the likelihood of a specific token, or a series of tokens, appearing within an extended sequence. When visualizing a token as a word, the model discerns the probabilities of diverse words or word combinations filling in a given blank space. This "sequence of tokens" isn't confined to just a word or two; it might span entire sentences or even multiple sentences.
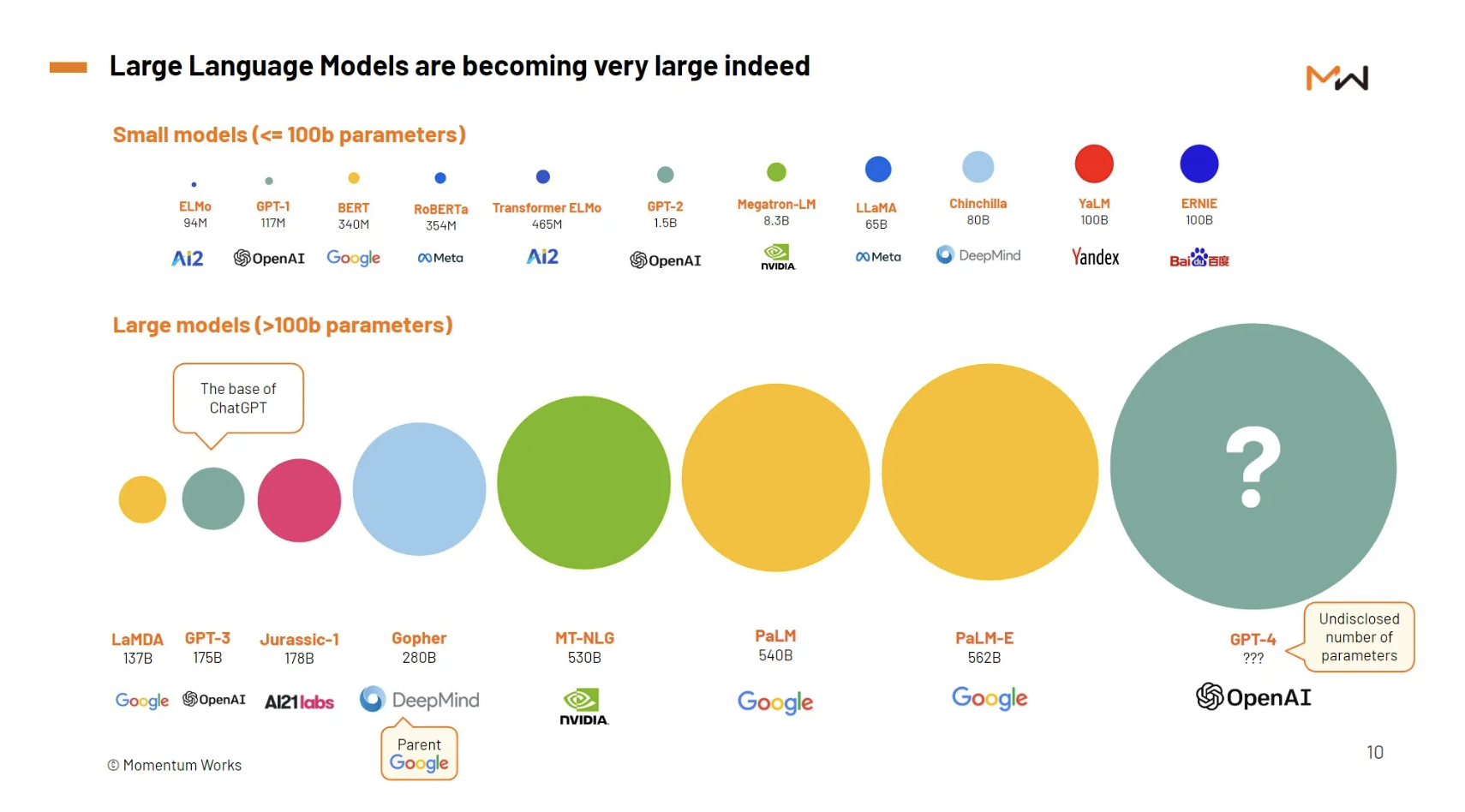
Human language, with its intricate nuances and vast scope, demands sophisticated and resource-heavy modeling. A marked trait of these LLMs is that as they expand in size, they also escalate in intricacy and efficiency. Whereas initial models were adept at anticipating the probability of individual words, contemporary large models can project probabilities for entire paragraphs or comprehensive documents.
The surge in the scale and prowess of language models in recent years is attributable to several factors: enhanced computer memory, elevated processing power, and the advent of innovative techniques adept at modeling extensive text sequences. These computing advancements are important because one of the defining attributes of LLMs is their vast array of parameters. Conceptualizing these parameters can be likened to a knowledge reservoir that the model accrues during its learning journey. It is this repository of insights that steers the model's nuanced understanding and response mechanisms.
Training Large Language Models: A Two-Step Process
Analogous to the human cognitive process, these models undergo an initial phase of pre-training, followed by meticulous fine-tuning. These stages can be explained in the following way:
● Training Phase: Every LLM begins its life with the training phase, akin to a rehearsal for ML models. This process exposes the model to vast volumes of unlabelled textual data with the primary objective of determining the subsequent word in a sentence or deciphering hidden words in a sequence. This phase is crucial as it enables the LLM to grasp linguistic patterns and structures. By delving deep into grammar, syntax, and semantics, the model begins to discern the intricate relations between words, laying a robust groundwork for comprehension. This iterative process, which often spans numerous cycles or epochs, gauges the model's prowess against a distinct validation dataset, ensuring it doesn't merely memorize but genuinely learns.
● Inference Phase: Having established foundational knowledge through training, the LLM now enters the fine-tuning or inference stage. Here, the model undergoes training on data pertinent to a distinct task, refining its parameters to enhance output precision and deciphering data to make informed predictions. Like a seasoned professional, the model incorporates the inputs, processes it through the parameters it has cultivated, and culminates in a coherent output, be it a specific classification or a prediction.
Issues with Training Large Language Models
While the development of AI (and AGI) is fraught with ethical and political dilemmas, a very tangible risk posed by AI's capital-intensive nature is the centralization of power among a few key companies. The inherent network effects, coupled with economies of scale derived from vast data infrastructures, could potentially empower dominant entities in the AI sector to impose restrictive gatekeeping measures, either by levying exorbitant fees or lobbying for regulatory capture. Such patterns are becoming increasingly discernible, especially given the escalating demand for machine learning model training and the associated computational needs.
As a cornerstone of machine learning operations, Graphics Processing Units (GPUs) are pivotal in the success of an AI model, aiding both in the training and inference stages. As we enter into Q4 2023, the insatiable appetite for computational resources, fueled by AI and ML technologies, remains unabated.
Additionally, as ML continues to weave its influence across diverse domains, from curated social media feeds to pivotal medical decision-making processes, its complexities increasingly find themselves hidden behind private companies/APIs. Legitimate reasons for doing so exist, like protecting the sanctity of data privacy, particularly when models are trained on sensitive user data like medical records. However, the more likely scenario is that the company is looking to safeguard proprietary algorithms for monetization.








