
10% of the queries are employing the new algorithm based on the Natural Language Processing (NLP) techniques
The search engine giant has been in the news recently with its proclamation that it achieved Quantum supremacy with its Sycamore quantum computer (53-qubit processor). The paper published in the prestigious journal Nature by Google, states that Sycamore performed a random number generation-related calculation in just 200 seconds — which would have taken the fastest existing supercomputer over 10,000 years!
Although Google’s biggest quantum computing competitor, IBM was not forthcoming in accepting the claim, citing that the former did not consider plentiful disk storage & other optimization methods. Nevertheless, the rebuttal from IBM did acknowledge the fact that it was a significant advancement towards Quantum computing-based future.
“Google’s experiment is an excellent demonstration of the progress in superconducting-based quantum computing,” but it shouldn’t be viewed as proof that quantum computers are ‘supreme’ over classical computers.” ~ IBM researchers
The quantum supremacy news, however, overshadowed another significant change that Google rolled out soon after this announcement. Based on cutting-edge NLP techniques developed by the in-house team of the search engine giant, a new search algorithm has been in the process of being implemented for the past 10 months.
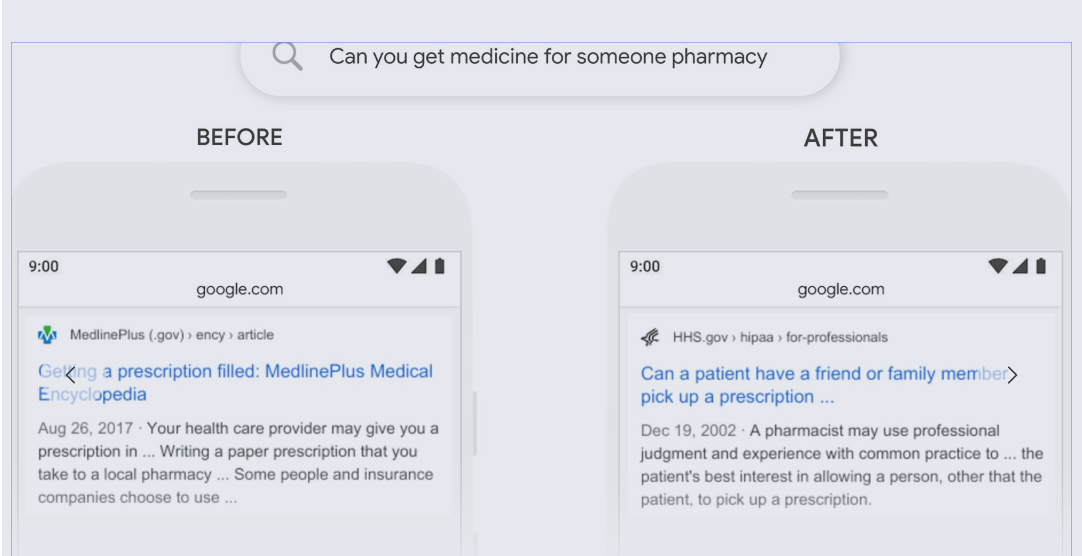
Dubbed as BERT — ‘Bidirectional Encoder Representations from Transformers’ is a refined & sophisticated version of the older core search algorithm, where the latter basically treated a sentence as a string of words looking for important words to return the closest local results. A comparison of the search difference between the older model & BERT can be seen above.
The new algorithm doesn't weed out some of the words from the query as being “unimportant.” BERT tries to understand the context of the words as they are used in the query to return the results that most closely match the query. BERT model, when applied to both ranking and featured snippets, will do a much better job at finding the most useful information.
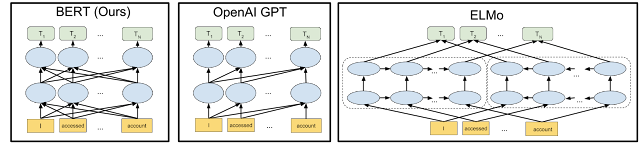
BERT is an open-source pre-training NLP technique, which has built on the work in other similar models like Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. BERT, however, has the advantage of being the World’s first deeply bidirectional, unsupervised language representation, pre-trained using only plain text. It can also be used to train other sophisticated question-answering systems, based on different models in as little as 30 minutes.
A common problem with machine learning techniques has been the bias of their training models and while Google is adamant that the use of NLP technique is not going to increase the bias, some of the ranking methodologies of its search results based on a varied number of tools including BERT has been intentionally kept mysterious by Google which raises some questions.
All changes are going to go through some quality control tests to ensure the new technique is actually improving the search results. For now, BERT will be deployed for one in ten searches in the U.S. in English, with support for more languages & areas to come in the future.
Medium | Twitter | LinkedIn | StockTwits | Telegram









{kind=link}