
In this post we consider how to build a linear regression model from a dataset to make predictions of a numerical value. Linear regression models belong to the category of supervised learning methods. This means that we have two sets of labeled data, one with input variables and the other with an output variable for which values are known. We split randomly the dataset on two datasets, the first called a training set and the second called a testing set. On the training set we train the model using known values of the output variable. We calculate an error metric which we try to minimize. A good analogy is a learning process of using tests with known answers. If we give the correct answer, this means we learned a topic. If our answer is incorrect, this means we need to learn more to pass the test.
The first regression model will try to predict an amount of a tip from an amount of the total bill in a restaurant. The second regression model will try to predict an amount of a tip from a number of people sitting at the same table (table size). The third regression model will try to predict an amount of a tip from both an amount of the total bill and the total number of people sitting at the same table.
To use these models you need python3 and the following packages: seaborn, numpy, pandas, sklearn. If you do not know how to install them see [1-2].
The script below loads the packages. Then it loads data and selects tips and amounts of bills. Then it splits randomly the data on two datasets: train and test. On the first dataset (train) it trains the model to give the minimal error and on the second dataset (test) it tests the performance of the model.
Copy the script below into a file model1.py and run it with the command: python3 model1.py. Python is very sensitive to TABs, therefore make sure that all TABs in the code are preserved in the file model1.py. If during a coping process TABs were replaced on spaces you should delete the spaces and insert TABs.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
def RMSerror(predicted,expected):
z=np.sqrt(np.mean((predicted - expected) ** 2))
print("RMS: %s" % z)
tips=sns.load_dataset('tips')
X=tips.drop('tip',axis=1).values
x=tips[['total_bill']].values
y=tips['tip'].values
lr=LinearRegression()
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)
print(x_train.shape,y_train.shape,x_test.shape,y_test.shape)
res1=lr.fit(x_train,y_train)
print("res1=",res1)
y_predict=lr.predict(x_test)
print("tip=f(total_bill)=intercept+koef*total_bill")
RMSerror(y_predict,y_test)
print("intercept=",lr.intercept_, "koef=",lr.coef_)
#visualize
import matplotlib.pyplot as plt
fig,ax=plt.subplots()
plt.scatter(x,y)
ax.axline((0,lr.intercept_),slope=lr.coef_,label='regression line')
ax.legend()
plt.show()
You will see the results on the screen.

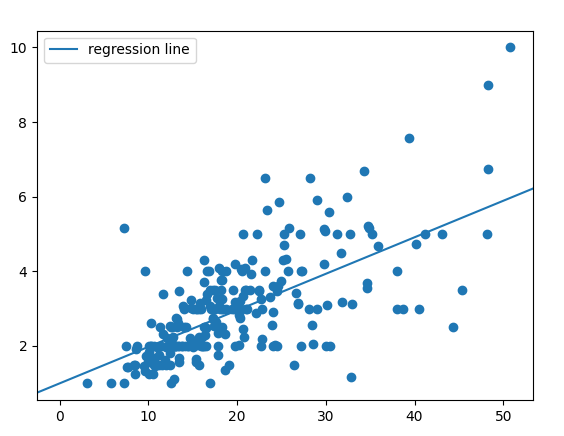
The first model has a root mean square (RMS) error equals to 0.9047.
Copy the script below into a file model2.py and run it with the command: python3 model2.py
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
def RMSerror(predicted,expected):
z=np.sqrt(np.mean((predicted - expected) ** 2))
print("RMS: %s" % z)
tips=sns.load_dataset('tips')
X=tips.drop('tip',axis=1).values
x=tips[['size']].values
y=tips['tip'].values
lr=LinearRegression()
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)
print(x_train.shape,y_train.shape,x_test.shape,y_test.shape)
res2=lr.fit(x_train,y_train)
print("res2=",res2)
y_predict=lr.predict(x_test)
print("tip=f(size)=intercept+koef*size")
RMSerror(y_predict,y_test)
print("intercept=",lr.intercept_, "koef=",lr.coef_)
#visualize
import matplotlib.pyplot as plt
fig,ax=plt.subplots()
plt.scatter(x,y)
ax.axline((0,lr.intercept_),slope=lr.coef_,label='regression line')
ax.legend()
plt.show()
You will see the results on the screen.

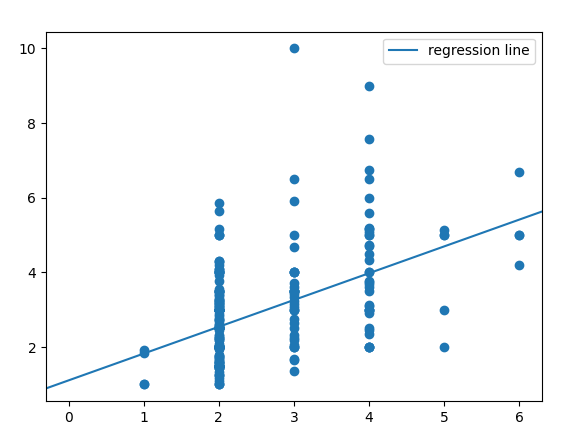
The second model has a root mean square (RMS) error equals to 1.1956.
Copy the script below into a file model3.py and run it with the command: python3 model3.py
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
def RMSerror(predicted,expected):
z=np.sqrt(np.mean((predicted - expected) ** 2))
print("RMS: %s" % z)
tips=sns.load_dataset('tips')
y=tips['tip'].values
X=tips.drop('tip',axis=1).values
df=pd.DataFrame(X, columns=['total_bill','sex','smoker','day','time','size'])
df1=df.filter(['total_bill','size'])
X_train,X_test,y_train,y_test=train_test_split(df1,y,random_state=0)
print(X_train.shape,y_train.shape)
lr=LinearRegression()
res3=lr.fit(X_train,y_train)
print("res3=",res3)
y_predict=lr.predict(X_test)
print("tip=f(total_bill,size)")
RMSerror(y_predict,y_test)
print("intercept=",lr.intercept_, "koef=",lr.coef_)
You will see the results on the screen.

The third model has a root mean square (RMS) error equals to 0.92467.
The first model shows the smallest root mean square error.
References:
[1] How to install python
https://realpython.com/installing-python/
https://www.codecademy.com/article/install-python3
[2] How to install pip3
https://www.activestate.com/resources/quick-reads/how-to-install-and-use-pip3/








