Merkle trees are smth that people already know (for anyone else, will explain them at the end of the article), but I'm sure you doesn't know everyyhing about. And NO, it isn't Angela Merkel's tree, that was only a joke !
I think you didn't click for reading why I've choosen writing this article,but for reading it, so I start it NOW !
Uses
M. Trees are widely used. let's see some of their most common uses.
1st use : Block pruning
When we delete many transactions, but we only should keep some, standard hashes won't run (it treats block as a single one file/data). With a merkle tree, we only have to keep "branchs" containing tx
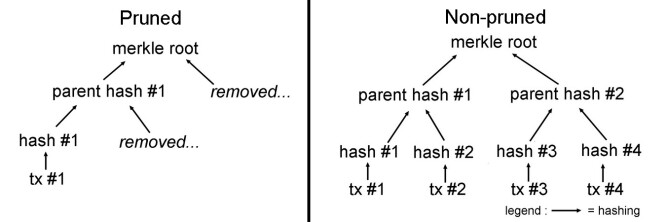
2nd use : big volumes checksums
When an hash will treat an entire hard disk as a big data, users will have to re-compute full partition hash (it might take hours for big hard disks) for editing a 100 bytes text note, a merkle root can treat files as single datas, so editing this same file will only involve re-computing its hash and parent hashes (=hashing less than some kB), that will only take a few seconds.
Problems
Each solution gives new problems (so researchers still have a job haha), and m. trees doesn't skip this share.
1 - Tree model
Like each tree (the trees with wood) has different branches, all merkle trees doesn't have the same branches, either it have same data or not.
This schema may help you with :
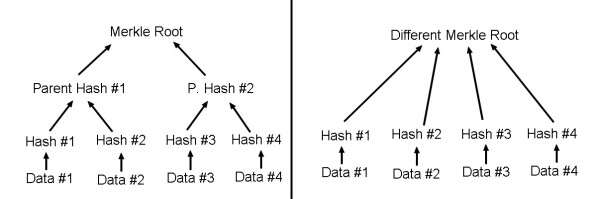
As you see, a same root shows that data are same, but a different root without seeing tree scheme doesn't say data are different.
2 - Not efficient for often checks
Because of we also have to store intermediary hashes (or at least path), using this model makes it more complicated.
I said it saved resources for creating checksum, but I forgot saying it wasted for checking. It's because of verifying data (with standard hash) is taking all the files, then hashing them, but with a m. system, we have to take files and compute p. hashes, and do it until root.
How does it run ?
At the beginning of the article, I talked about making an explanation at the end of the article. It's here.
Merkle Trees are a way for hashing data that allows adding data or deleting some without unvaliding hash.
For example, if we have a list of words : I, love, publish0x, I will take the hashes of these words :
sha256(I)=a83dd0ccbffe39d071cc317ddf6e97f5c6b1c87af91919271f9fa140b0508c6c
sha256(love)=686f746a95b6f836d7d70567c302c3f9ebb5ee0def3d1220ee9d4e9f34f5e131
sha256(publish0x)=28fb9f790341220b13571084eb09e1aaf69c625ead01e7d2b56f513e97b06619
then, I will compute the hash of these 3 hashes :
sha256(a83dd0ccbffe39d071cc317ddf6e97f5c6b1c87af91919271f9fa140b0508c6c, 686f746a95b6f836d7d70567c302c3f9ebb5ee0def3d1220ee9d4e9f34f5e131, 686f746a95b6f836d7d70567c302c3f9ebb5ee0def3d1220ee9d4e9f34f5e131) = 6c417e5bc8bcf22270d519817a3770f2189d15f20f29a2f5333638ff39c5a5c2
so 6c417e5bc8bcf22270d519817a3770f2189d15f20f29a2f5333638ff39c5a5c2 is the merkle root of this list
On a schema, it gives that :
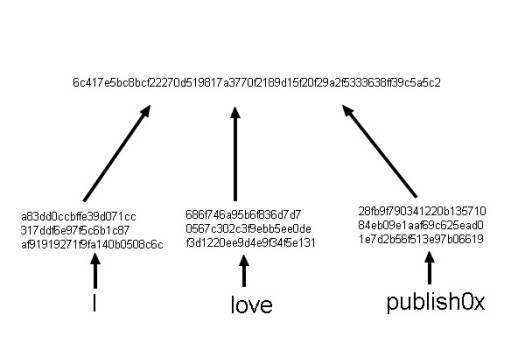
That's all
I said all I wanted to say. I hope that you learned smth in.
If you did, please give a tip and a like (it's very rewarding)
And if you see smth to add/improve, feel free of saying it in the comments